Abstract
Ensuring laboratory safety is a critical challenge due to the presence of hazardous materials and complex operational environments. In this paper, we present an autonomous laboratory inspection robot (ALARMbot) leveraging foundation models for intelligent safety management. The system integrates a mobile platform, multi-modal sensors, and a 6-DoF manipulator. By fusing LiDAR-based mapping with vision-and-language models, the robot achieves semantic navigation and fine-grained functional zone recognition. A hierarchical framework combines YOLOv8-OBB visual perception (achieving 91.2% mAP on custom datasets) with vision-language risk reasoning for real-time hazard detection. The robot autonomously intervenes in operable risks with an average response time of 8.5 seconds and navigates complex laboratory layouts with a 97.5% success rate. Extensive real-world experiments demonstrate reliable navigation, accurate risk detection, and effective hazard mitigation. This work offers a practical solution for intelligent laboratory safety and highlights the advantages of foundation models in autonomous inspection robotics.
Hardware Design
The hardware architecture consists of three integrated modules: a mobile chassis, perception sensors, and a manipulation subsystem. A ROS-driven mobile platform integrating a wheeled chassis with RGB-D cameras, LiDAR and a 6-DoF robotic arm fitted with an adaptive gripper. All perception, planning and control modules run on a central compute unit, with SSH-based communication enabling real-time remote monitoring.
Navigation
The navigation system is designed to enable the robot to autonomously navigate through complex laboratory environments. It utilizes a combination of LiDAR-based mapping and vision-and-language models for semantic navigation and functional zone recognition.
Navigation Architecture
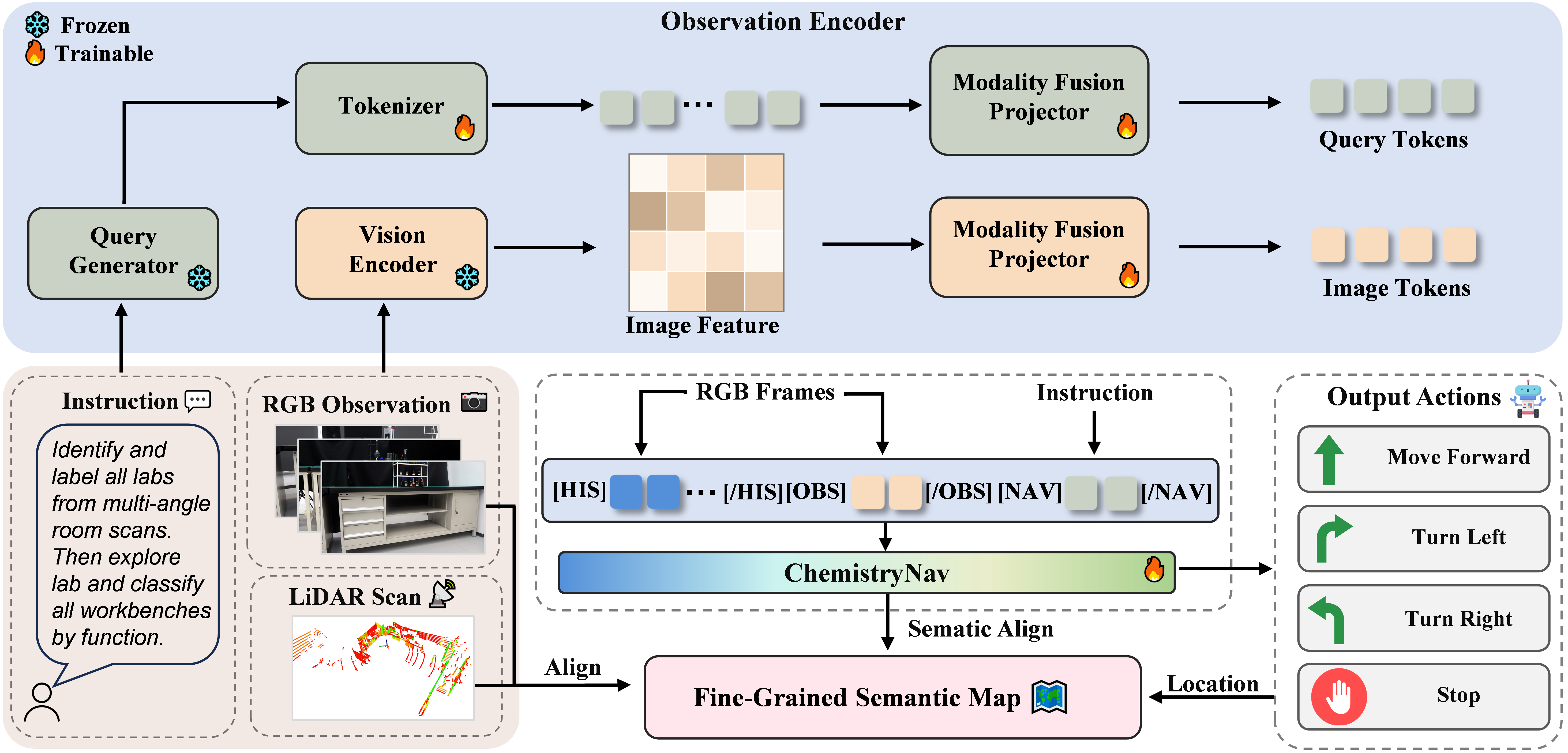
Based on navigation instructions and multimodal sensor inputs—including RGB images and LiDAR scans—the system generates query tokens and image tokens through dedicated Modality Fusion Projectors, integrating them within a unified Observation Encoder. At each timestep, ChemistryNav processes both historical and current observations alongside navigation-oriented tokens to produce explicit navigation actions. Real-time robot positions, acquired via precisely calibrated LiDAR sensors, are dynamically aligned with an evolving Fine-Grained Semantic Map, providing comprehensive semantic and spatial information essential for effective dynamic route planning and targeted risk management tasks.
Full-floor Exploration
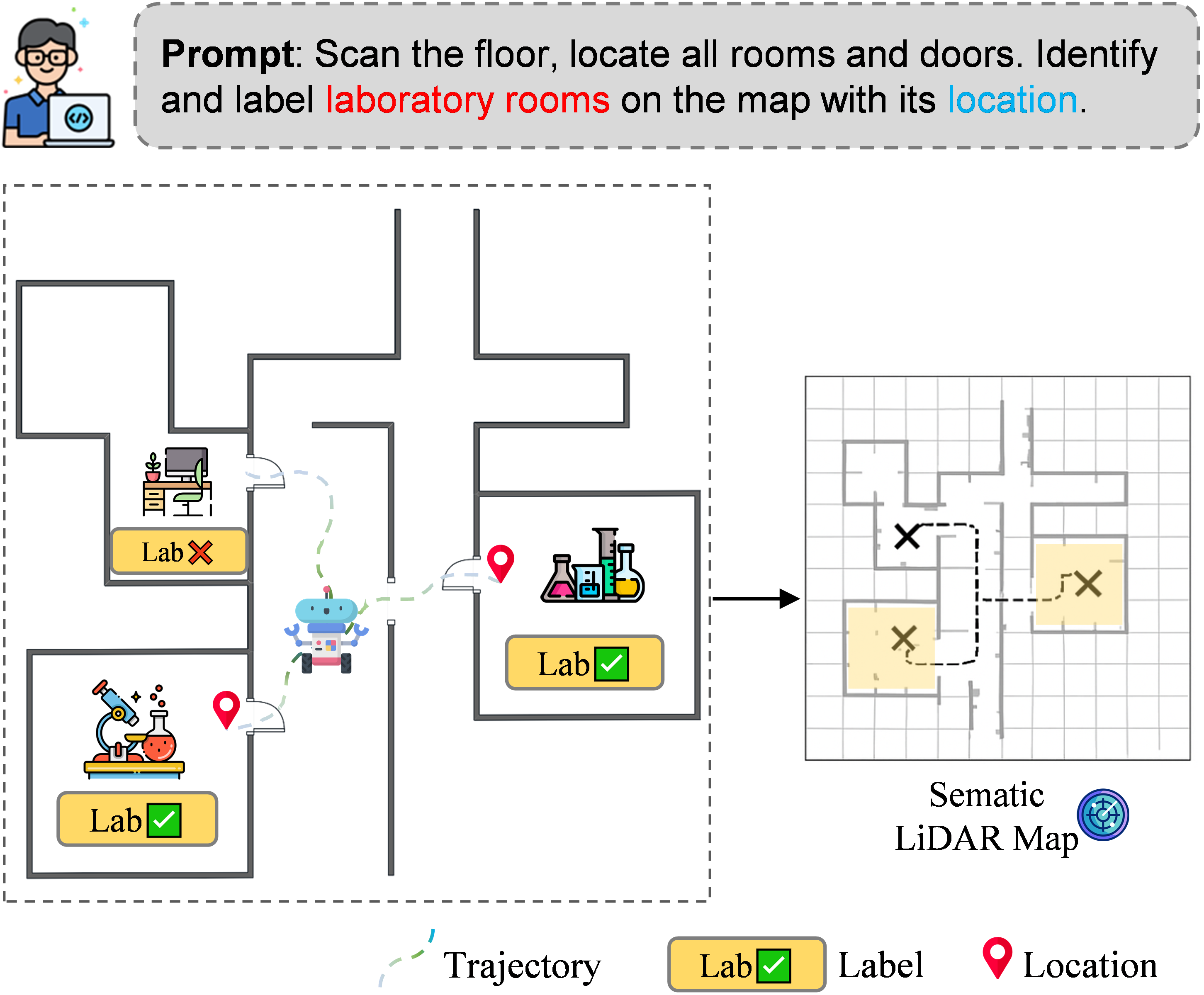
User prompts trigger the robot to visit each room, record whether it is a laboratory, tag its location, and store the data for designing a comprehensive cross-room inspection route. The robot autonomously explores the entire floor, generating a complete semantic map showing the spatial distribution and functional categorization of work areas. This map is continuously updated as the robot navigates, allowing for real-time adjustments to its path and actions.
Functional Zone Annotation

Inspection
A two-stage detection framework with a YOLO-based Visual Perception Module and a VLM-based Risk Reasoning Module to detect objects and assess hazards in real-time. The results are sent to the Inspect Agent, which plans actions or archives data, and uploads risk assessments and outcomes to the Interaction UI for monitoring.
Detection
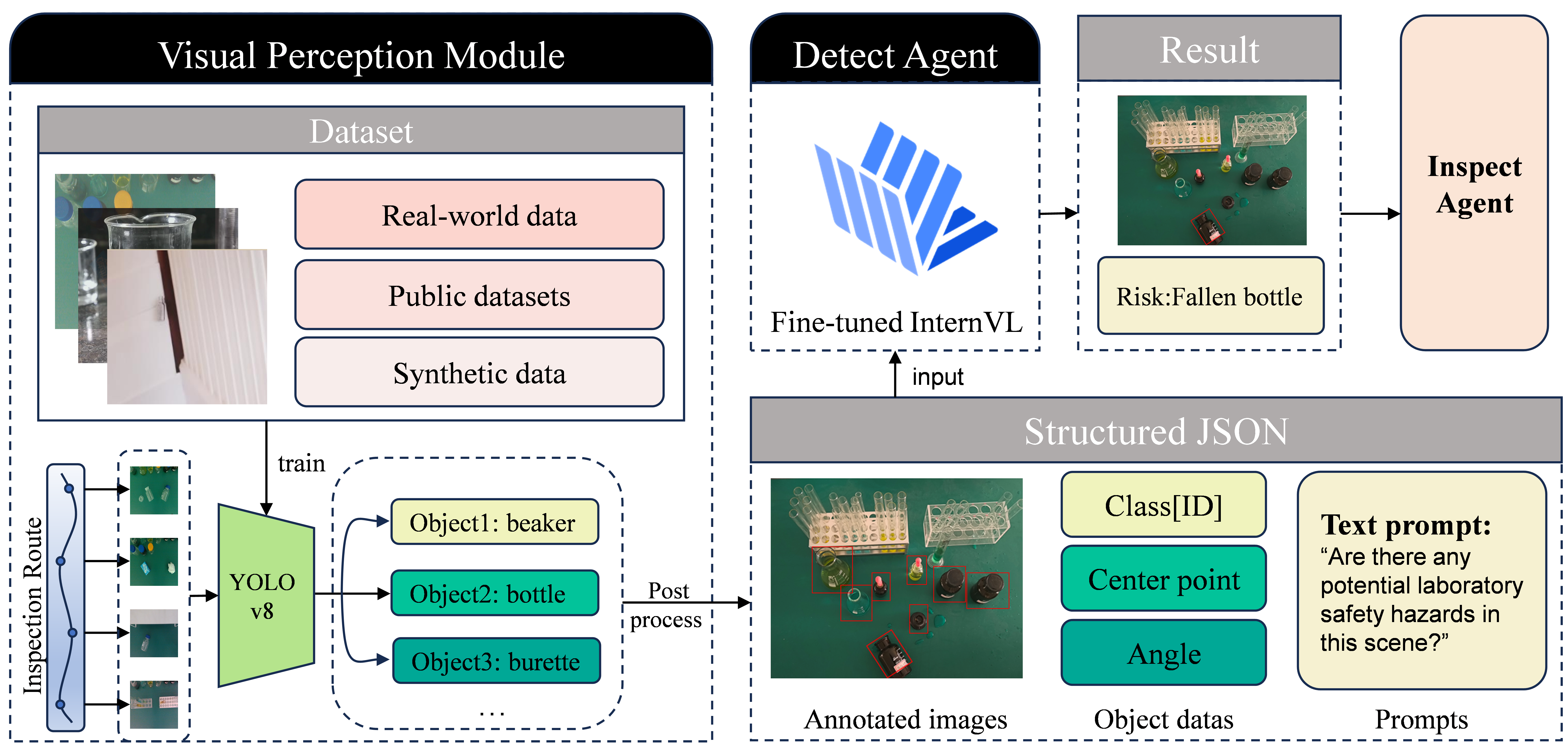
Manipulation
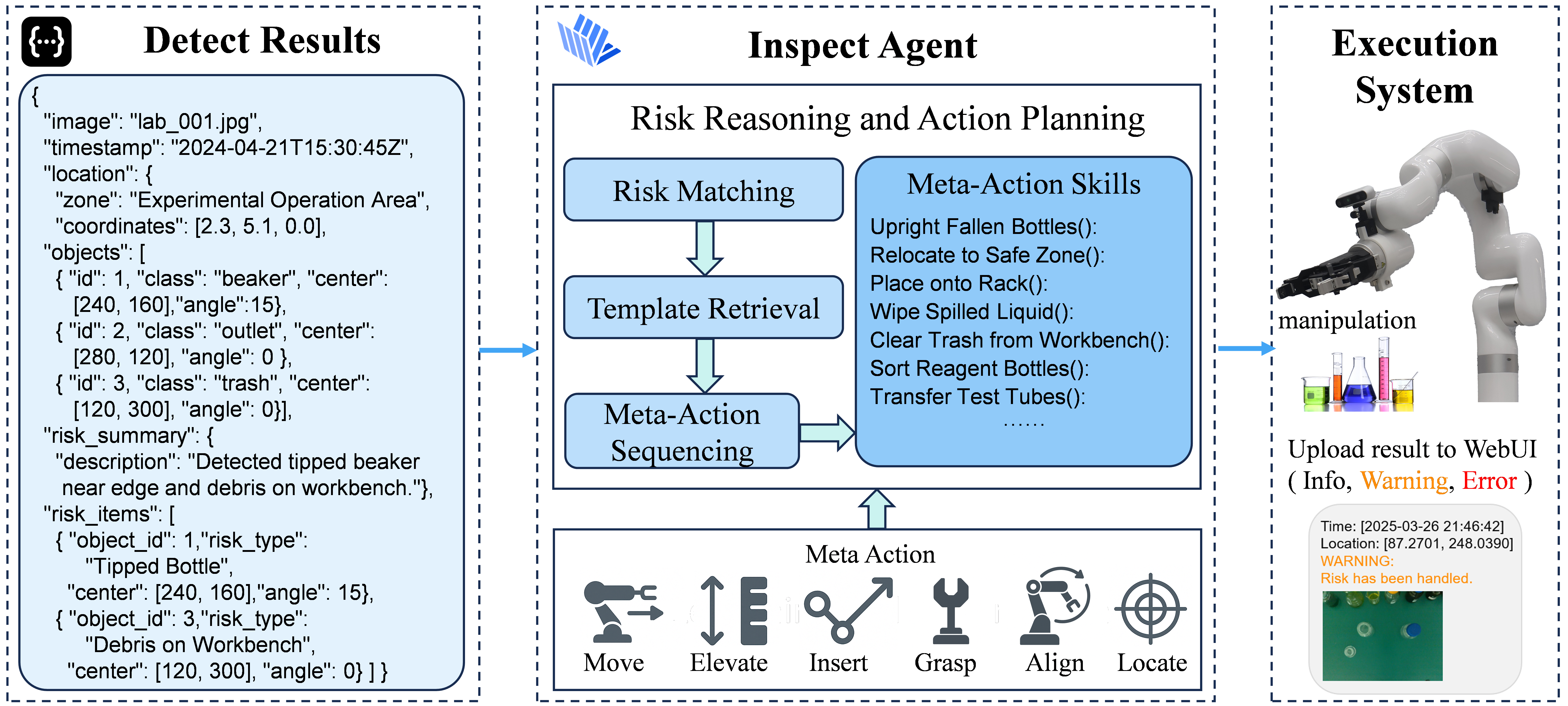 The Inspect Agent receives structured detection results containing identified objects and inferred risks.
It performs risk reasoning and action planning through three stages: Risk Matching, Template Retrieval, and Meta-Action Sequencing.
Based on predefined Meta-Action Skills, the system composes executable motion sequences, which are then carried out by the robotic manipulator.
Execution results, including success or warnings, are uploaded to the Interaction UI for monitoring and logging.
The Inspect Agent receives structured detection results containing identified objects and inferred risks.
It performs risk reasoning and action planning through three stages: Risk Matching, Template Retrieval, and Meta-Action Sequencing.
Based on predefined Meta-Action Skills, the system composes executable motion sequences, which are then carried out by the robotic manipulator.
Execution results, including success or warnings, are uploaded to the Interaction UI for monitoring and logging.
Experiments
We evaluate our robotic system in unfamiliar laboratory environments, testing navigation, risk detection, and risk elimination. An intuitive human-robot interface accepts natural-language commands, ensuring stable and precise task execution.
Navigation Performance
We designed a real-world experiment where the robot autonomously explores an entire floor and searches for a specified laboratory. The robot autonomously explores large-scale spaces, identifies laboratory characteristics, and records the locations of rooms that qualify as laboratories. As a result, the robot successfully navigated the entire floor, planned the exploration route, and found the specified laboratory.
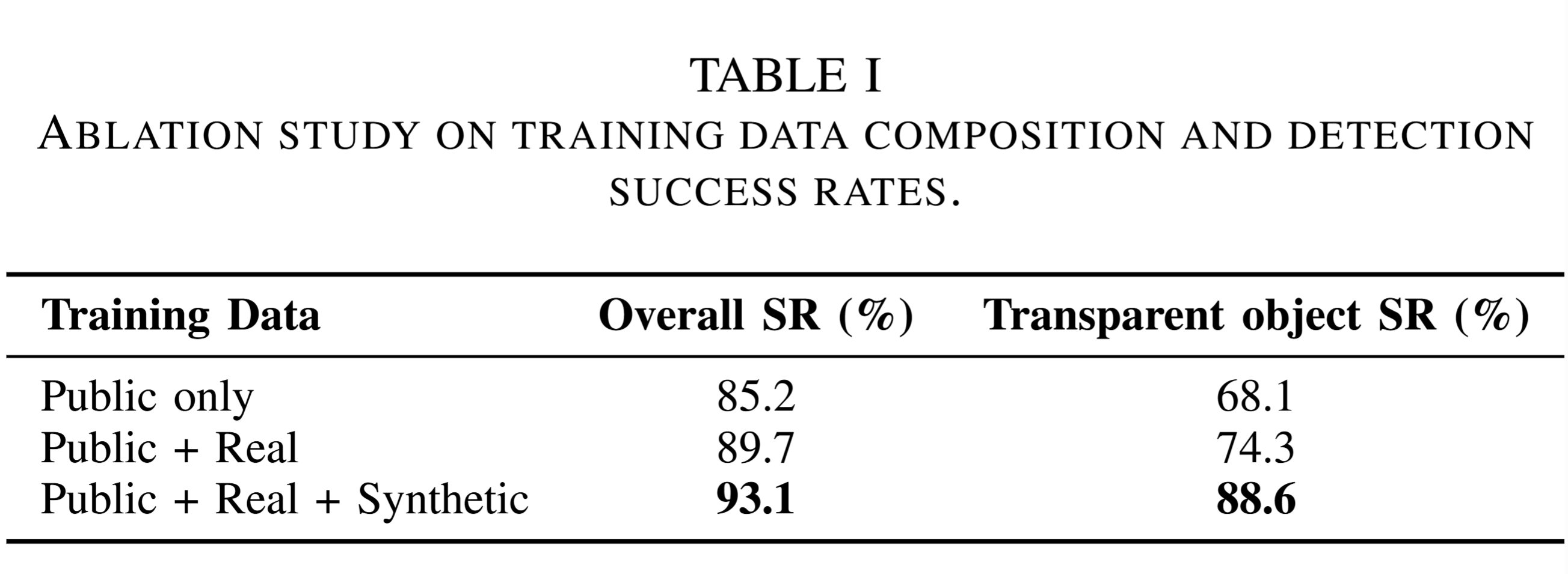
Detection Performance
We compared the risk detection success rates compared three configurations: Public only, Public + Real, and Public + Real + Synthetic. By using small models trained on diverse datasets, the system achieves better accuracy in risk identification.
Manipulation Performance
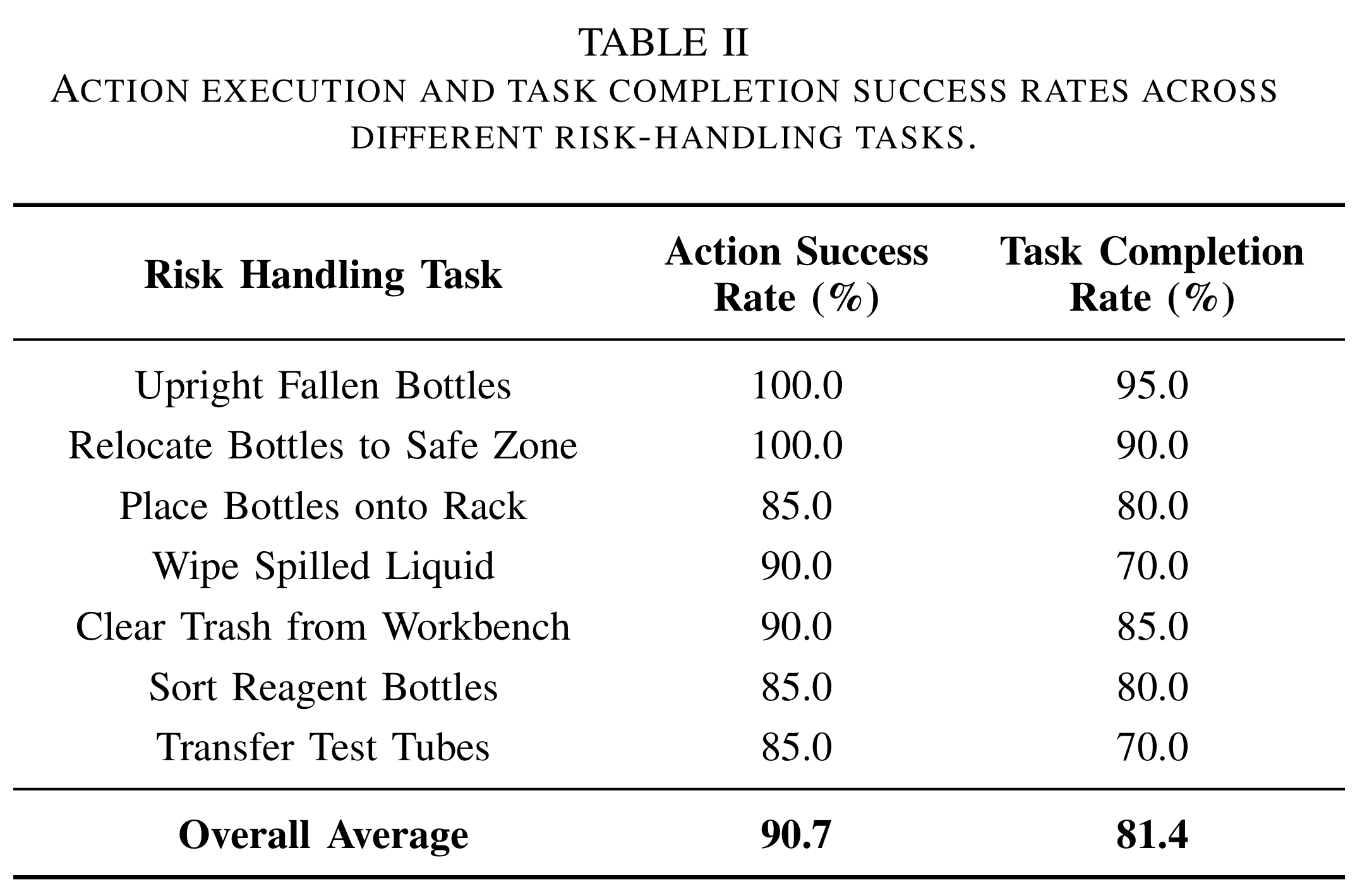
We designed various meta-action-based manipulation experiments to equip our robot with basic laboratory risk mitigation capabilities, including
upright fallen bottles, relocate edge-exposed objects, place tipped bottles onto racks, wipe spilled liquids, and clear debris from workbenches.
Additionally, we validated some fundamental laboratory operations, such as sorting unclassified reagent bottles and transferring misplaced tubes,
enabling it to perform a variety of essential laboratory tasks.
We provide operation videos from multiple perspectives for various tasks.
Front View
Side View
Before Operation
After Operation
Unright Fallen Bottles


Reload to Safe Zone


Place onto Rack


Wipe Spilled Liquid


Clear Trash


Sort Reagent Bottles

Transfer Test Tubes
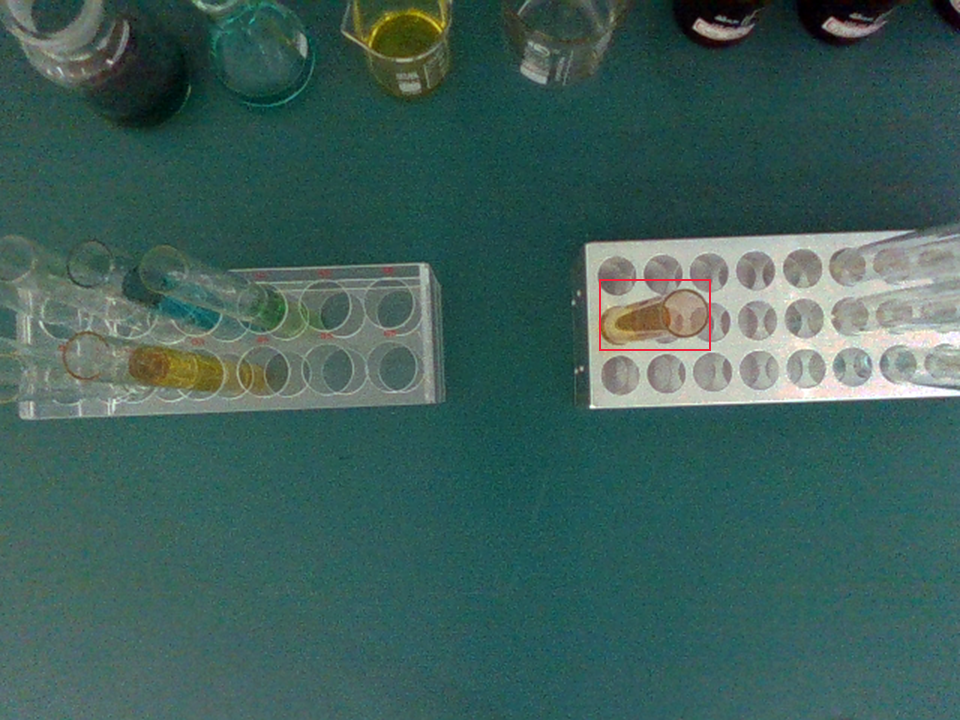
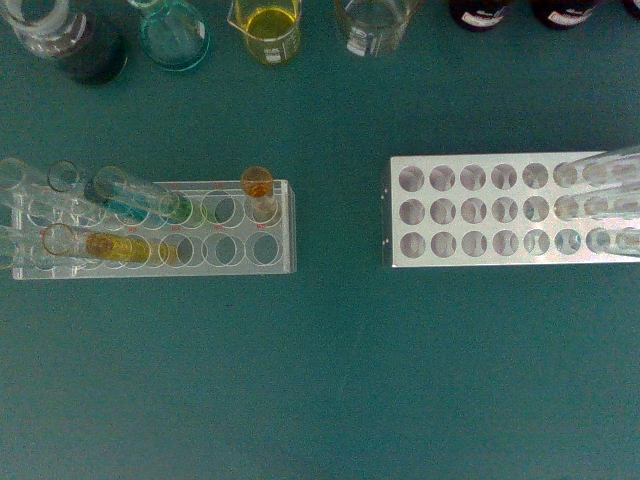
We achieved high success rates across various tasks, which demonstrate the effectiveness of combining vision-language reasoning with meta-action sequence control for autonomous laboratory risk mitigation, while also identifying opportunities for further improvements in precision-critical manipulations.
Inspection Performance
We designed a comprehensive inspection experiment. During the inspection process, the robot autonomously plans the inspection route and performs risk identification and handling in each zone. For operable risks, the robot autonomously intervenes; for inoperable risks, the robot reports them to human operators. Additionally, we developed a human-robot interaction interface, allowing operators to control the robot using natural language commands for inspection tasks, while the robot provides real-time feedback on its current status and operation results through the interface.
Conclusion and Future Work
We propose the ALARMbot, which unites a LiDAR-equipped mobile base, RGB-D perception, and a 6-DoF manipulator within a ROS framework to deliver semantic-aware navigation,
real-time hazard detection, and autonomous intervention in laboratory settings. Powered by foundation vision-language models and YOLOv8-OBB (91.2 % mAP),
the system handles risks in an average of 8.5 s and completes inspection routes with a 97.5 % success rate,
proving both reliable and effective for intelligent safety management.
Future work will extend the methodology to other high-risk domains—industrial plants, chemical warehouses—and explore multi-robot collaboration,
continual learning for dynamic environments, and richer human-robot interaction to create more scalable, adaptive safety solutions.